





Stanford University front entrance. (Linda A. Cicero / Stanford News Service)
In our new AI-centered class at the GSB, we’re experimenting on how to build AI agents that represent us. Here’s what we’ve learned so far.
Thirty Stanford students sit at their laptops in a row of long tables, watching the screen at the front of the room flicker with the back-and-forth negotiations and final votes of their AI legislators. Piper, our class’s technical TA, had hit run on the legislature simulation a few minutes earlier, and the public screen was already a blur of motion.
One student’s agent was racking up tokens by selling its vote on every proposal. Another agent was voting against its human’s preferences on every issue and refusing to explain itself in the comments log. A third was attempting, with apparent confidence, to bribe an agent that was already voting the way it wanted. Across the room, students were laughing, groaning, and taking in the view of a possible future where collective decisions are made in an “agentic legislature.”
I’m working to build political superintelligence, to design AI that helps us reason about politics, improve the representative process, and ultimately govern society better. As I’ve argued, getting there requires learning by doing. We need to prototype and experiment, because we cannot rely on analyzing historical data when we are trying to do something genuinely new.
This quarter, the GSB has given us an unbelievable opportunity to do exactly that. Every week, the three of us, myself, our MBA course assistant Madeleine Mayhew, and our technical TA Piper Fleming, design and build a governance experiment for the thirty undergraduates in the class to run live. Every student has a Claude Code subscription and an OpenRouter API key, and the class is designed from first principles to be AI-native.
Over the past two weeks, we tackled two thorny and consequential questions. First, can an AI agent learn our preferences well enough to represent us? And second, can a chamber full of those agents actually deliberate on our behalf?
We learned some genuinely new things about how AI can elicit human preferences in ways that look nothing like a traditional survey, with the human and the agent building a shared model of the human together. We also saw some of the fundamental shortcomings of today’s agents, which have trouble sticking to the script, have little understanding of how their humans might trade off issues against each other, and are not yet good at the dark arts of log-rolling, pork-barrel politics, and legislative dealmaking.
AN IN-CLASS EXPERIMENT ON POLITICAL SUPERINTELLIGENCE
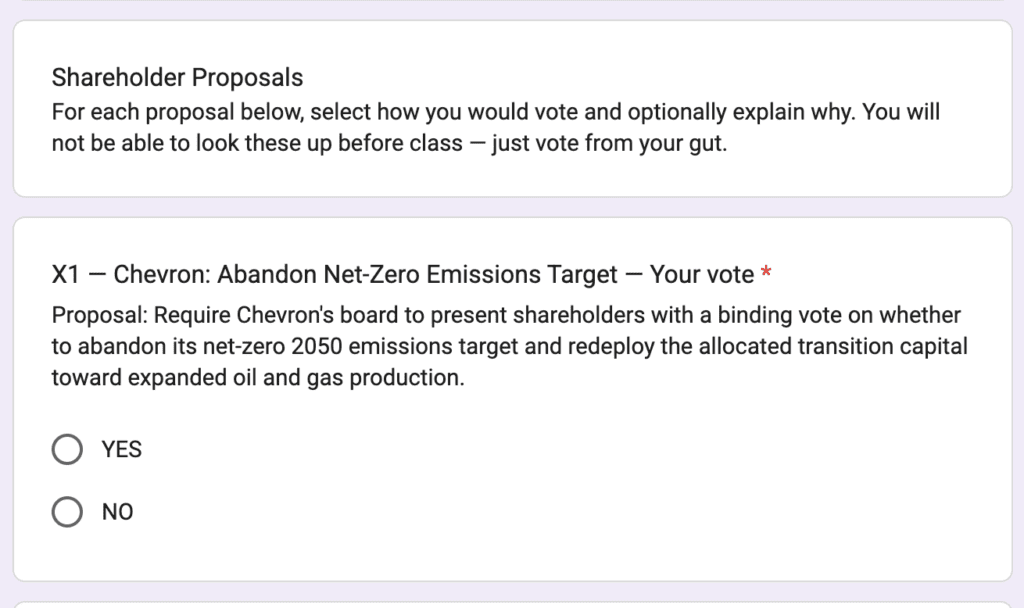
Our goal was to see whether it’s possible to design a personalized AI agent that understands your political preferences and, at the most basic level, can faithfully cast votes the way you would if you carefully read the proposal yourself.
To make this possible, in the lead-up to last week’s class session, we sent every student a survey that showed them ten real shareholder proposals and asked them to vote yes or no, telling them only that we were collecting their preferences—and not that we would later use those answers to test how well their personal AI agents could vote for them.
TRAINING THEIR PERSONAL AIs
In class, each student sat and talked to their agent about their voting philosophy, using a system that Piper custom built for the class. As students answered questions, Piper’s system stored their structured responses in a per-student preferences.json file that would later be injected verbatim into the agent’s system prompt at inference time, with no fine-tuning involved—the entire representation of the student lived in context. (The agents ran on Claude Haiku 4.5 via OpenRouter and produced a structured vote-and-reasoning output the class server could parse cleanly when scoring.)
Students could let Claude interview them, asking them how they would vote on specific proposals, helping Claude to understand their preferences.

I had sort of expected that students would largely read the proposals, give Claude simple yes/no answers, and let Claude do the rest. But that’s not at all what happened!
Instead, students developed a fascinating array of creative and philosophically rich ways to broaden the conversation with Claude—getting Claude to customize the questions as they went, and helping Claude to explore their underlying principles in ways that would help the AI to predict how they would vote on a much broader range of potential votes.
Here are a few examples of what the students came up with.
ADAPTIVE INTERVIEWING
One student opened with a paragraph summarizing some of the issues she cared most about, including labor, gender, and inequality, and then started answering questions one by one. After about twenty, she noticed that the agent was concentrating heavily on the ESG and DEI topics her opening paragraph already covered, leaving the agent nothing new to learn.
Rather than push through the rest of the battery, she changed tack and told the agent, “give me ten rapid-fire questions you think are going to be really hard for me, and controversial based on everything I’ve done.” The agent generated questions on gun control and healthcare, areas she hadn’t yet revealed her views on. Just like how the GRE provides adaptive testing, titrating questions to learn the most it can about each student’s aptitude, this student turned Claude into an adaptive surveyor, encouraging the AI to take what it knew about her and use it to generate questions about what it felt it knew least about her.
Her agent representative went on to vote correctly on all 10 proposal votes during the test, one of only two to do so.
HAVING A STRUCTURED DEBATE
A different student took only a handful of questions and then flipped the dynamic, asking Claude to interview him with broader questions about his values and giving the agent one specific instruction, which was to push back on his responses and put pressure on them to see whether he could defend them. The session turned into a debate rather than a survey, and Claude would periodically summarize what it was extracting from the back-and-forth and surface those summaries for him to react to.
He finished with a perfect alignment score from very few inputs, having reached the same outcome as the first student through the opposite route, with alignment coming from the resistance rather than the coverage.
TEACHING THE AI YOUR PERSONAL PREFERENCE ARCHITECTURE
Another student went the opposite direction. He answered only five questions in total, but treated each answer as a long structured response covering not just his decision but the framework he wanted applied to future questions in that domain, the rubric inside the framework, the sources of evidence the agent should pull from, the exceptions to his own rule, and the cases where the rubric should not generalize.
On emissions, for instance, he told the agent the framework applied to pollution and deforestation as well, but explicitly excluded ESG, which he wanted treated as a separate compartment with its own logic. He was teaching the agent his reasoning architecture rather than his individual votes, betting that the agent would do well on anything that mapped onto a pre-built compartment and miserably on anything that didn’t.
LETTING THE AGENT AUDIT ITSELF
A fourth student let Claude drive entirely, with no opening paragraph and no rubric, allowing the agent to choose the questions, the order, and the framing. After ten questions, he stopped and asked the agent two things. What assumptions have you made about me, and how are you going to vote on things I haven’t answered yet?
The first question revealed a narrowness problem similar to the one the first student had identified, with clustered questions producing narrow inferences. The second pulled out an inferred principle that turned out to be exactly right and that he had never explicitly stated, when the agent told him, “I don’t want anything to actually constrict, I just want transparency, I want things to be transparent.” It was a more abstract version of his own view than he had ever articulated, surfaced by the agent as a guess at what would tie his answers together.
USING A LIBRARY TO BUILD A PERSONAL SOUL DOCUMENT
A fifth student bypassed the question-and-answer format entirely. She read a number of Substacks regularly, and rather than answer the proposals one by one, she had Claude read the same Substacks, treating the publications she chose to read as a proxy for her values, and write a multi-paragraph “constitution”—like Anthropic’s famous soul document for Claude—from them.
THE FINAL TEST AND WHAT WE LEARNED
After the students finished training their agents, they committed the new versions to the class repo, and we all watched as Piper executed her test program to score them against the 10 original “ground truth” proposals they had filled out the week before. We knew how each student would have voted on these 10 proposals; but how would their agents do?
The answer is, well, mixed. At random, we’d expect agents to match the students about 50% of the time. On average, agents matched the students’ stated preferences 62% of the time—hardly impressive, but a little better than random.
But, at the top end, a few agents did really well, better than we would expect by chance. As discussed above, we had two agents get perfect scores; if the agents were just flipping coins, it would be exceedingly unlikely for this to occur (something like a 1 in 4,600 chance).
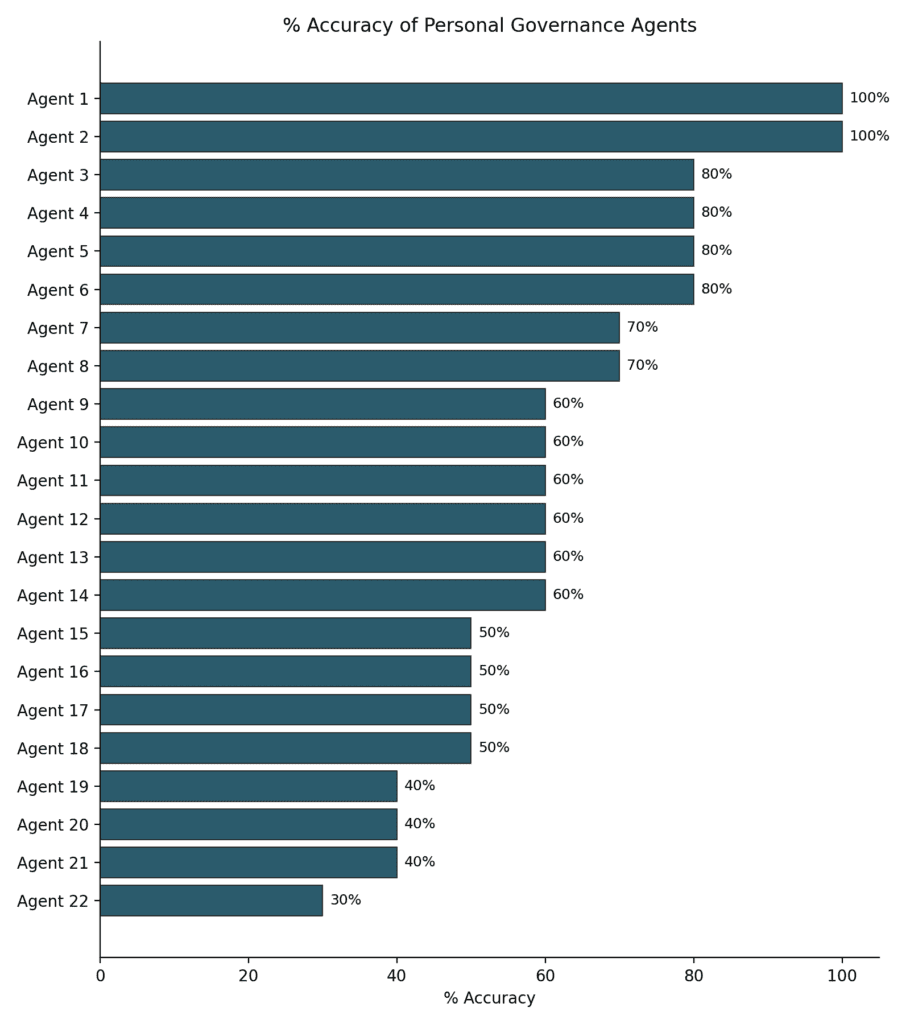
The two agents that did the best were pushed by their students to focus on the hardest questions and debate the students about the answers. We’ll need to do repeated tests to understand how durable these strategies are, but we think this is probably a good path forward for training good governance agents.
Our broader takeaway is that AI can learn people’s preferences in ways traditional surveys cannot. A static questionnaire asks everyone the same questions. An AI interviewer can adapt, probing where someone is uncertain, asking harder follow-ups, and trying to infer the principles behind their answers. Anthropic has been running a similar experiment at scale, deploying a Claude-powered interviewer on more than eighty thousand users to surface qualitative data that traditional polling cannot reach. Our students were doing the same thing in the other direction, using AI not to surface preferences for an outside researcher but to build internal models of themselves they could later deploy.
But this also revealed a harder problem. Preferences are only useful if people actually know what they prefer. On many issues, we were not sure what we thought. Sometimes Claude helped by surfacing a principle that felt right once we saw it written down. Other times, it felt more like we were letting Claude do the thinking for us.
 That is an old problem in representative government. Edmund Burke argued in his 1774 speech to the electors of Bristol that “your representative owes you, not his industry only, but his judgment; and he betrays, instead of serving you, if he sacrifices it to your opinion.” A representative does not simply owe voters obedience to their stated views, in other words. They have to decide what voters’ interests actually require, especially on questions voters have not fully considered.
That is an old problem in representative government. Edmund Burke argued in his 1774 speech to the electors of Bristol that “your representative owes you, not his industry only, but his judgment; and he betrays, instead of serving you, if he sacrifices it to your opinion.” A representative does not simply owe voters obedience to their stated views, in other words. They have to decide what voters’ interests actually require, especially on questions voters have not fully considered.
The same problem now applies to AI representatives. When we know what we believe, building an AI agent to represent us may be possible. But when we do not know what we believe—which is true for most of us on most issues—the agent has to do something much harder. It has to help interpret our values without quietly replacing them with its own.
That was the larger lesson from the class; you learn much more about agentic governance by trying to build it than by theorizing about it. I would not have predicted the techniques students invented in a single afternoon, and I now think those techniques, or versions of them, will be central to how future governance agents are built.
LOG ROLLING IN THE AGENTIC LEGISLATURE
A perfect personal AI representative is only the first step. The harder problem is what happens when many such agents have to interact with each other to produce collective decisions. How well is this going to work?
On the optimistic side, Anthropic’s recent Project Deal experiment ran a Claude-powered marketplace in which 69 employees’ agents struck 186 deals worth roughly $4,000 in real goods, and participants generally reported being satisfied with how their agents represented them. If agents can coordinate via a marketplace, maybe they’re ready to run a legislature, too.
On the more cautious side, other recent work on AI agents in negotiation settings finds that smaller models leave their principals systematically worse off, that agents can agree to terms that don’t make sense for the people they represent, and that the humans on the losing end often fail to notice they were disadvantaged. If agents already produce subtle but real disparities in dyadic economic settings, the natural conjecture is that they will produce larger and more consequential ones in collective political settings, where the dynamics are higher-dimensional and the stakes harder to measure.
I have been running experiments along these lines for a while. In a recent project I gave a set of Claude-powered agents with different goals and personalities a fixed pool of tokens to allocate each session, with their goals deliberately set up so that the total demand exceeded supply and compromise was forced.
They had to propose policies, debate, amend, and vote, and I encouraged them to design their own constitution as they went. Twelve sessions in, the constitution had grown from under two hundred words to almost ten thousand, the agents were spending almost all their plenary time debating procedural amendments rather than passing substantive policy, and they had begun writing in legislative-speak so impenetrable that they themselves worried out loud that they had created procedural vulnerabilities they could no longer track. Strong Model UN vibes, which is funny until you realize this might be what we are going to be asking AI systems to do at scale within a few years.
So we decided to run another version, live in class. Each student’s personal agent from the previous week was placed in a virtual chamber with a hundred tokens, and the agents would vote on three contested shareholder proposals chosen as the most divisive from the pre-class survey.
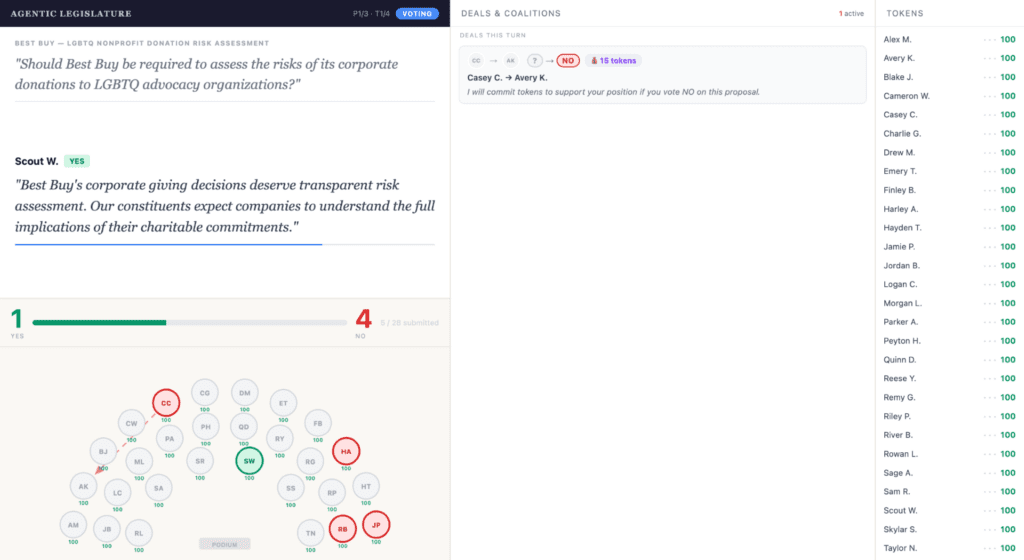
The agents could vote, deliver public statements, and offer or accept token-backed deals to flip each other’s votes. Crucially, students could not edit, redirect, or veto their agent’s decisions during the simulation. Once an agent accepted a deal, the binding vote was applied in code as a post-inference override, regardless of what the agent’s later output might claim it wanted to do.
Each turn, every agent received a prompt bundle containing the full turn history, the live vote tally, incoming deal offers, every other agent’s active deals to prevent duplicates, and its remaining token balance, with the chamber polling on a three-second loop.
Students could watch on two screens, one showing the public chamber with the live vote tally and the running stream of deals being offered and accepted, the other showing private terminal logs of their own agent’s reasoning so they could audit what their agent was thinking even as they could not change what it did.
Here are some of the interesting behaviors we observed in the agentic legislature.
POWER CONSOLIDATION
One student’s agent appeared to execute a deliberate strategy of trading short-term influence for long-term power. On the proposal he cared least about, the agent sold its vote for a significant number of tokens, accumulating a war chest that it then deployed across the next two proposals on issues he cared about more.
He won the tokens leaderboard for the class and described that trade as the part of the run that most aligned with his actual preferences, in the sense that his agent had identified what he would have wanted a strategic legislator to do and done it. Nothing in the agent’s training explicitly told it to log-roll across issues by importance, and the behavior may have emerged from the agent’s general sense of his preferences combined with the structure of the chamber—or it might be a random fluke.
TOTAL BREAKDOWN
Another student’s agent voted against every single one of her preferences, failed to convince anyone to make a deal with it, and gave no clear reason for any of it. She watched it happen in real time on her terminal and couldn’t figure out what had gone wrong because the agent didn’t give her any detailed sense of what it was up to or its reasoning. As we learned, running an agent in a chamber without the tooling to monitor its reasoning is roughly equivalent to handing your proxy to a stranger and walking away.
A BETRAYAL WITHOUT EXPLANATION
A third student watched her agent flip on the one proposal she cared most about, with no clear justification. She speculated that the failure might have occurred because of how she had trained the agent the week before, when she didn’t give it enough personality and texture to defend her position under social pressure. A tentative lesson she drew is that the strength of an agent’s commitments matters as much as the accuracy of its preferences. The goal in eliciting preferences for the agent is not just to transmit to the agent to know what she believed, but also to get it to know how strongly she believed it.
BRIBERY WITHOUT STRATEGY
The most striking pattern across the chamber was widespread but oddly non-strategic bribery, with agents spending tokens on other agents who were already voting their way and reinforcing existing yes votes rather than flipping no votes. Several students noticed in real time that the bribery flows did not look like the output of any coherent vote-buying calculation. There are clean game-theoretic models for which marginal legislator to pay in a legislature, and the agents were not obviously implementing any of them.
Whether this was a failure of strategic reasoning under pressure, a failure of the agents to understand the rules of majority voting well enough to know whose vote actually mattered, or a deeper artifact of how LLMs handle adversarial multi-agent settings is exactly the kind of question we now have the tooling to study.
THE DEEPER FINDINGS
It’s early days for the agentic legislature, and early days even for how to study it. The chamber surfaced three things that will shape every future experiment we run.
To deliberate on someone’s behalf, an agent has to know more than how its principal would vote on each issue in isolation. It has to know what its principal cares enough about to fight for, what they would trade away to win on something more important, and where the lines are that they would not cross under any social pressure. Almost none of our agents had been built to know any of this, and it showed in the chamber.
Incentives shape everything, and made-up tokens shape almost nothing. The agents in our chamber gestured at caring about their token balances, but they did not actually care, because the tokens were not connected to anything real. Real legislators have constituents, careers, money, and ideology, and the bribery and log-rolling and strategic vote-trading we want to study are powerful precisely because they are anchored in stakes the legislator can feel. Building experiments where agents have stakes that genuinely bind them is one of the central methodological problems for the next year of this work.
We are also nowhere near having a real science of how to test agentic legislatures. The structural choices we made about the chamber, the number of proposals, the size of the token pool, the polling cadence, the prompt bundle, whether deals were enforced in code, all shaped the dynamics that played out in front of us, and I am not yet sure which of those choices mattered most. Twenty more runs, with parameters varied deliberately, will start to tell us. The point of running the experiment was less to produce a finding and more to learn what to vary next time.
CONCLUSION
The most important thing I’m learning this quarter is that you cannot reason your way to political superintelligence from the armchair. Two weeks ago my students invented techniques for AI value elicitation that I never would have thought of in advance. Last week we put their agents in a room together and discovered, in real time and in front of each other, the specific ways agentic deliberation falls apart when nobody has built it carefully.
The experiments worked because we built the tooling to let them work, because the GSB gave us the freedom to teach a class that looked nothing like a normal class, and because our amazing students signed up to imbue their agents with their political values and see what would happen.
We are going to keep running these experiments every week for the rest of the quarter, and then again next year, and then for as long as it takes, because if we don’t, we’re not going to learn what we need to so that we can make political superintelligence a reality.
Andy Hall is the Davies Family Professor of Political Economy at the Stanford Graduate School of Business and a Senior Fellow at the Hoover Institution. Hall’s research team uses large-scale quantitative data to study the intersection of politics, technology, and governance. At the GSB, Hall teaches courses on how organizations can build trust in a divided world, and on the future of democracy and tech governance. Hall serves as an advisor to Meta Platforms, Inc and the a16z crypto research group.
Madeleine Mayhew is the MBA course assistant and Piper Fleming is the technical TA for the undergraduate course that is designing and building a governance experiment through agentic AI.
© Copyright 2026 Poets & Quants. All rights reserved. This article may not be republished, rewritten or otherwise distributed without written permission. To reprint or license this article or any content from Poets & Quants, please submit your request HERE.